Попередньо виготовлені бібліотеки Illumina


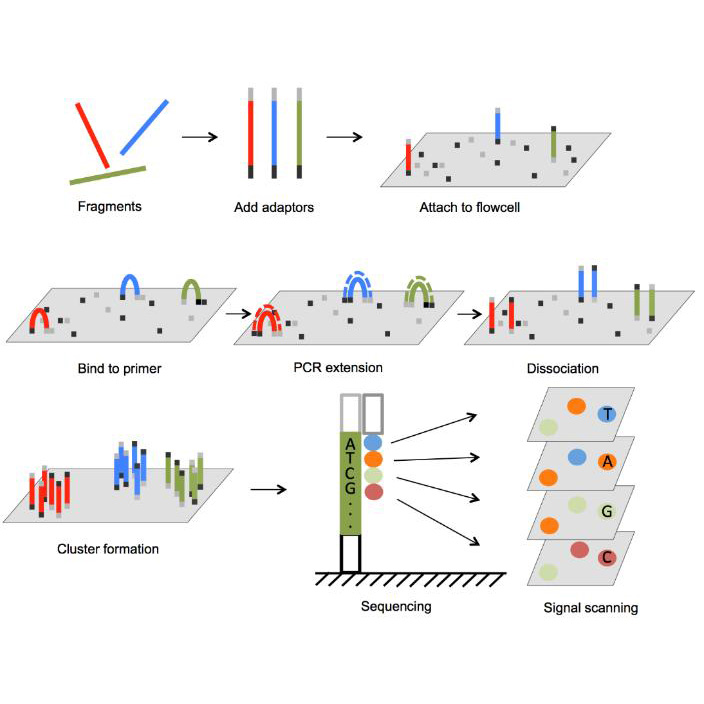
Особливості
●Платформи:Illumina Novaseq 6000 та Novaseq X Plus
●Режими послідовності:PE150 та PE250
●Контроль якості бібліотек перед секвенуванням
●Послідовність даних QC та доставки:Доставка звіту про QC та необроблені дані у форматі FASTQ після демульплексування та фільтрації Q30 читає
Переваги послуг
●Універсальність послуг секвенування:Замовник може вибрати послідовність за допомогою смуги протоки, проточної комірки або за кількістю необхідних даних (часткове секвенування смуги).
●Великий досвід роботи на платформі послідовності Illumina:з тисячами закритих проектів з різними видами.
●Доставка звіту про секвенування QC:з показниками якості, точністю даних та загальною продуктивністю проекту секвенування.
●Процес зрілого послідовності:з коротким часом повороту.
●Суворий контроль якості: Ми реалізуємо суворі вимоги КК, щоб гарантувати надання послідовно якісних результатів.
Зразкові платформи
| Платформа | Проточна клітина | Режим послідовності | Одиниця | Орієнтовний вихід |
| Novaseq x | 10b (8 смуг) | PE150 | Єдиний провулок Часткова смуга | 375 Гб / провулок |
| 25b (8 смуг) | PE150 | Єдиний провулок Часткова смуга | 1000 ГБ/провулок | |
| Novaseq 6000 | Проточна клітина SP (2 смуги) | PE250 | Проточна клітина Єдиний провулок Часткова смуга | 325-400 м читає / провулок |
| Проточна клітина S4 (4 смуги) | PE150 | Проточна клітина Єдиний провулок Часткова смуга | ~ 800 ГБ / провулок |
Вимоги до вибірки
| Сума даних (x) | Концентрація (qpcr/нм) | Обсяг | |
| Часткове секвенування смуги
| X ≤ 10 Гб | ≥ 1 нм | ≥ 25 мкл |
| 10 ГБ <X ≤ 50 ГБ | ≥ 2 нм | ≥ 25 мкл | |
| 50 ГБ <X ≤ 100 ГБ | ≥ 3 нм | ≥ 25 мкл | |
| X> 100 Гб | ≥ 4 нм | ≥ 25 мкл | |
| Секвенування смуги | На провулок | ≥ 1,5 нм / бібліотечний пул | ≥ 25 мкл / бібліотечний пул |
Крім концентрації та загальної кількості, також потрібна відповідна пікова картина.
ПРИМІТКА: Послідовність смуг бібліотек низької різноманітності вимагає Phix Spike-In, щоб забезпечити надійний базовий дзвінок.
Ми рекомендуємо подати попередньо огороджені бібліотеки як зразки. Якщо вам потрібен Bmkgene для виконання бібліотечного об'єднання, зверніться до
Вимоги бібліотеки для часткового секвенування смуги руху.
Розмір бібліотеки (Пікова карта)
Основний пік повинен бути в межах 300-450 bp.
Бібліотеки повинні мати єдиний головний пік, відсутність забруднення адаптера та без димерів праймерів.
Будь ласка, зверніться до нас, якщо ваші зразки не відповідають початковим матеріальним вимогам.
РОБОТА РОБОТИ
Бібліотека контроль якості

Послідовність

Контроль якості даних

Доставка проекту
Бібліотека QC звіт
Звіт про якість бібліотеки надається перед секвенуванням, оцінкою суми бібліотеки та фрагментацією.
Послідовність звіту про QC
Таблиця 1. Статистика даних про секвенування даних.
| Зразок ідентифікатора | Bmkid | Сирого читання | Необроблені дані (ВР) | Чисті читання (%) | Q20 (%) | Q30 (%) | GC (%) |
| C_01 | BMK_01 | 22 870,120 | 6 861,036 000 | 96.48 | 99.14 | 94.85 | 36.67 |
| C_02 | BMK_02 | 14 717 867 | 4,415,360,100 | 96.00 | 98.95 | 93.89 | 37.08 |
Малюнок 1. Розподіл якості вздовж читань у кожному зразку

Малюнок 2. Розподіл базового вмісту

Малюнок 3. Розподіл вмісту зчитування в послідовності даних