Illumina förberedda bibliotek


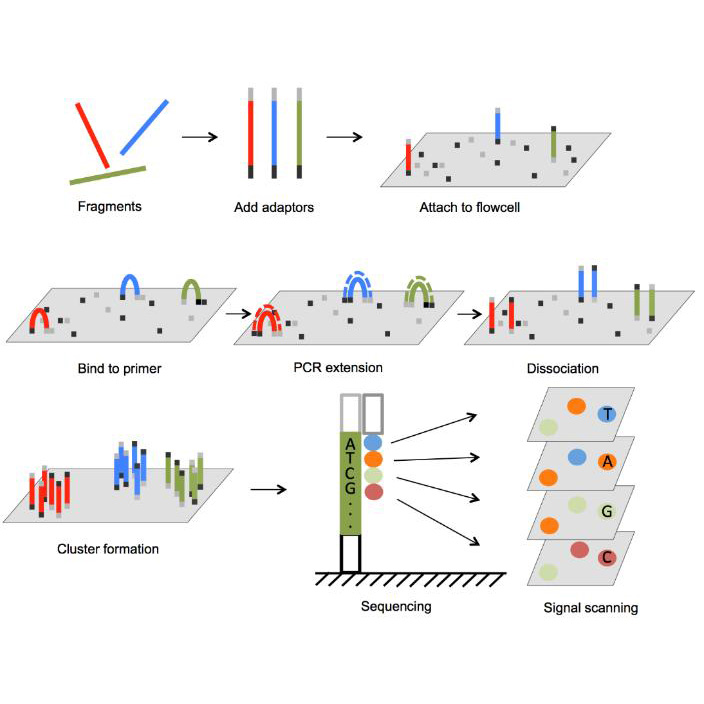
Drag
●Plattformar:Illumina Novaseq 6000 och Novaseq X Plus
●Sekvenseringslägen:PE150 och PE250
●Kvalitetskontroll av bibliotek före sekvensering
●Sekvenseringsdata QC och leverans:Leverans av QC -rapport och rådata i FASTQ -format efter demultiplexering och filtrering av Q30 -läsningar
Servicefördelar
●Mångsidighet för sekvenseringstjänster:Kunden kan välja att sekvensera med körfält, flödescell eller med mängd data som krävs (partiell spårsekvensering).
●Omfattande erfarenhet på Illumina -sekvenseringsplattform:med tusentals stängda projekt med olika arter.
●Leverans av sekvensering av QC -rapport:med kvalitetsmetriker, datanoggrannhet och sekvenseringsprojektets totala prestanda.
●Mogen sekvenseringsprocess:med kort vändningstid.
●Rigorös kvalitetskontroll: Vi implementerar strikta QC-krav för att garantera leverans av konsekvent högkvalitativa resultat.
Provplattformar
| Plattform | Flödescell | Sekvenseringsläge | Enhet | Uppskattad utgång |
| Novaseq x | 10b (8 körfält) | PE150 | Enfjädring Partiell körfält | 375 GB / körfält |
| 25b (8 körfält) | PE150 | Enfjädring Partiell körfält | 1000 GB/körfält | |
| Novaseq 6000 | SP flödescell (2 körfält) | PE250 | Flödescell Enfjädring Partiell körfält | 325-400 m läser / körfält |
| S4 flödescell (4 körfält) | PE150 | Flödescell Enfjädring Partiell körfält | ~ 800 GB / LANE |
Provkrav
| Databelopp (x) | Koncentration (qPCR/nM) | Volym | |
| Partiell spårsekvensering
| X ≤ 10 GB | ≥ 1 nm | ≥ 25 μl |
| 10 GB <x ≤ 50 GB | ≥ 2 nm | ≥ 25 μl | |
| 50 GB <x ≤ 100 GB | ≥ 3 nm | ≥ 25 μl | |
| X> 100 GB | ≥ 4 nm | ≥ 25 μl | |
| Spårsekvensering | Per körfält | ≥ 1,5 nm / bibliotekspool | ≥ 25 μl / bibliotekspool |
Förutom koncentration och total mängd krävs också ett lämpligt toppmönster.
OBS: LANE SEKSUKTION AV LÅGA DIVERSIKTION Bibliotek kräver Phix Spike-in för att säkerställa robust bassamtal.
Vi rekommenderar att du skickar in förspolade bibliotek som prover. Om du behöver Bmkgene för att utföra bibliotekspooler, se
Bibliotekskraven för partiell körfältsekvensering.
Biblioteksstorlek (toppkarta)
Huvudtoppen bör vara inom 300-450 bp.
Bibliotek bör ha en enda huvudtopp, ingen adapterföroreningar och inga primerdimerer.
Vänligen nå ut till oss om dina prover inte uppfyller utgångsmaterialkraven.
Serviceflöde
Bibliotekskvalitetskontroll

Sekvensering

Datakvalitetskontroll

Projektleverans
Bibliotek QC -rapport
En rapport om bibliotekets kvalitet tillhandahålls före sekvensering, utvärdering av bibliotekets belopp och fragmentering.
Sekvensering av QC -rapport
Tabell 1. Statistik om sekvenseringsdata.
| Prov -ID | Bmkid | Råa läsningar | Rådata (BP) | Rena läsningar (%) | Q20 (%) | Q30 (%) | GC (%) |
| C_01 | BMK_01 | 22 870,120 | 6 861,036 000 | 96.48 | 99.14 | 94.85 | 36.67 |
| C_02 | BMK_02 | 14,717,867 | 4 415 360,100 | 96,00 | 98.95 | 93.89 | 37.08 |
Bild 1. Kvalitetsfördelning längs läsningarna i varje prov

Bild 2. Basinnehållsfördelning

Figur 3. Fördelning av läsinnehåll i sekvenseringsdata