Illumina पूर्व-निर्मित पुस्तकालयहरू


सुविधाहरू
●प्लेटफार्महरू:Illumina NovaSeq 6000 र NovaSeq X Plus
●अनुक्रम मोडहरू:PE150 र PE250
●क्रमबद्ध गर्नु अघि पुस्तकालयहरूको गुणस्तर नियन्त्रण
●अनुक्रम डेटा QC र डेलिभरी:QC रिपोर्ट र कच्चा डाटाको वितरण फास्टक ढाँचामा डिमल्टीप्लेक्सिङ र Q30 रिडहरू फिल्टर गरेपछि
सेवा लाभहरू
●अनुक्रम सेवाहरूको बहुमुखी प्रतिभा:ग्राहकले लेन, फ्लो सेल, वा आवश्यक डाटाको मात्रा (आंशिक लेन अनुक्रमण) द्वारा अनुक्रम छनौट गर्न सक्छ।
●इलुमिना सिक्वेन्सिङ प्लेटफर्ममा व्यापक अनुभव:विभिन्न प्रजातिहरु संग हजारौं बन्द परियोजनाहरु संग।
●अनुक्रम QC रिपोर्ट को वितरण:गुणस्तर मेट्रिक्स, डेटा शुद्धता र अनुक्रम परियोजना को समग्र प्रदर्शन संग।
●परिपक्व अनुक्रम प्रक्रिया:छोटो घुमाउरो समय संग।
●कडा गुणस्तर नियन्त्रण: हामी लगातार उच्च गुणस्तरको नतिजाहरूको डेलिभरी सुनिश्चित गर्न कडा QC आवश्यकताहरू लागू गर्छौं।
नमूना प्लेटफार्महरू
| प्लेटफर्म | फ्लो सेल | अनुक्रम मोड | एकाइ | अनुमानित आउटपुट |
| NovaSeq X | 10B (8 लेन) | PE150 | एकल लेन आंशिक लेन | 375Gb / लेन |
| 25B (8 लेन) | PE150 | एकल लेन आंशिक लेन | 1000 Gb/लेन | |
| NovaSeq 6000 | एसपी फ्लो सेल (२ लेन) | PE250 | फ्लो सेल एकल लेन आंशिक लेन | ३२५-४०० एम रिड्स / लेन |
| S4 फ्लो सेल (4 लेन) | PE150 | फ्लो सेल एकल लेन आंशिक लेन | ~800 Gb / लेन |
नमूना आवश्यकताहरू
| डाटा रकम (X) | एकाग्रता (qPCR/nM) | भोल्युम | |
| आंशिक लेन अनुक्रमण
| X ≤ 10 Gb | ≥ 1 nM | ≥ 25 μl |
| 10 Gb < X ≤ 50 Gb | ≥ 2 nM | ≥ 25 μl | |
| ५० Gb < X ≤ १०० Gb | ≥ ३ nM | ≥ 25 μl | |
| X > 100 Gb | ≥ ४ nM | ≥ 25 μl | |
| लेन अनुक्रमण | प्रति लेन | ≥ 1.5 nM / पुस्तकालय पूल | ≥ 25 μl / पुस्तकालय पूल |
एकाग्रता र कुल रकमको अतिरिक्त, एक उपयुक्त शिखर ढाँचा पनि आवश्यक छ।
नोट: कम विविधता पुस्तकालयहरूको लेन अनुक्रमणिकालाई बलियो आधार कलिङ सुनिश्चित गर्न PhiX स्पाइक-इन आवश्यक छ।
हामी नमूनाको रूपमा पूर्व-पूल गरिएको पुस्तकालयहरू पेश गर्न सिफारिस गर्छौं। यदि तपाईंलाई पुस्तकालय पूलिङ गर्न BMKGENE आवश्यक छ भने, कृपया सन्दर्भ गर्नुहोस्
आंशिक लेन अनुक्रमणिका लागि पुस्तकालय आवश्यकताहरू।
पुस्तकालय आकार (शिखर नक्शा)
मुख्य शिखर 300-450 bp भित्र हुनुपर्छ।
पुस्तकालयहरूमा एउटै मुख्य शिखर, कुनै एडाप्टर प्रदूषण र प्राइमर डाइमरहरू हुनुपर्दछ।
कृपया हामीलाई सम्पर्क गर्नुहोस् यदि तपाइँका नमूनाहरूले सुरु हुने सामग्री आवश्यकताहरू पूरा गर्दैनन्।
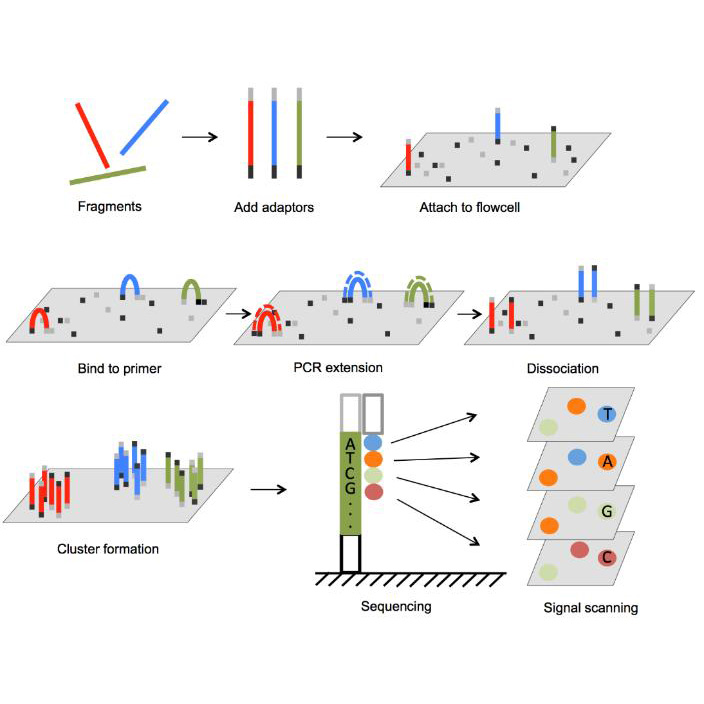
सेवा कार्यप्रवाह
पुस्तकालय गुणस्तर नियन्त्रण

अनुक्रम

डाटा गुणस्तर नियन्त्रण

परियोजना वितरण
पुस्तकालय QC रिपोर्ट
पुस्तकालयको गुणस्तरको प्रतिवेदन अनुक्रमणिका, पुस्तकालयको रकमको मूल्याङ्कन र खण्डीकरण गर्नु अघि प्रदान गरिन्छ।
अनुक्रम QC रिपोर्ट
तालिका 1. क्रमबद्ध डेटामा तथ्याङ्कहरू।
| नमूना आईडी | BMKID | कच्चा पढ्छन् | कच्चा डाटा (bp) | क्लीन रिड्स (%) | Q20(%) | Q30(%) | GC(%) |
| C_01 | BMK_01 | २२,८७०,१२० | ६,८६१,०३६,००० | ९६.४८ | ९९.१४ | ९४.८५ | ३६.६७ |
| C_02 | BMK_02 | १४,७१७,८६७ | ४,४१५,३६०,१०० | ९६.०० | ९८.९५ | ९३.८९ | ३७.०८ |
चित्र 1. प्रत्येक नमूनामा पढिएको गुणस्तर वितरण

चित्र २. आधारभूत सामग्री वितरण

चित्र 3. क्रमबद्ध डेटामा पढ्ने सामग्रीहरूको वितरण