

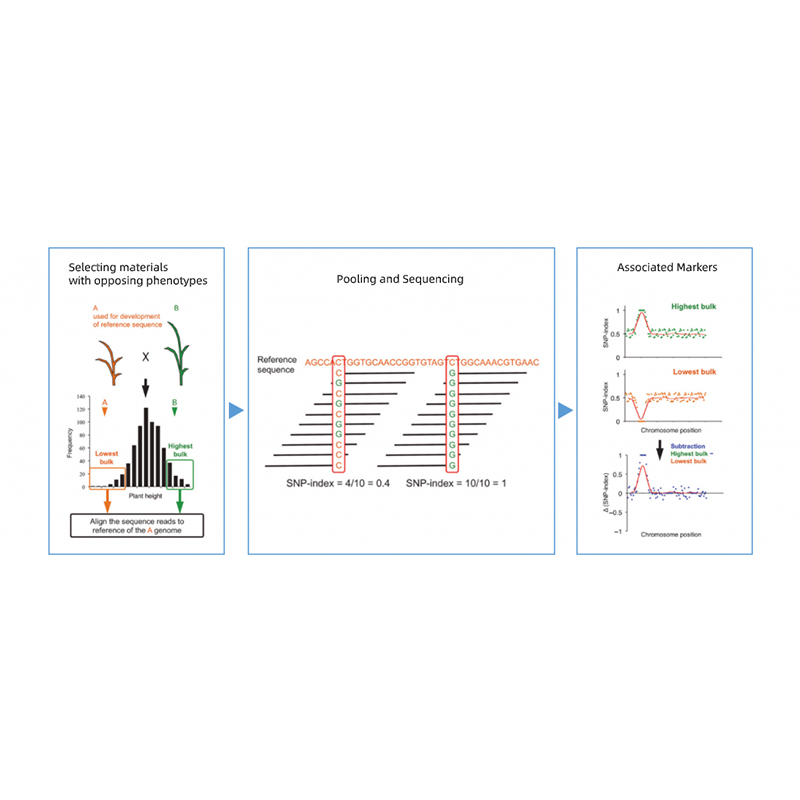
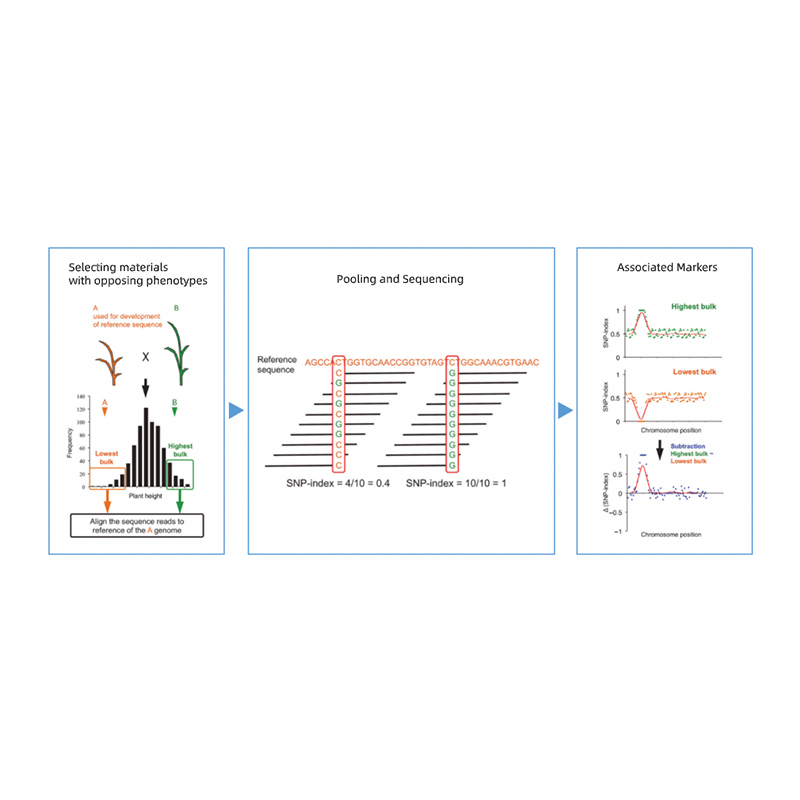
Analyse des ségrégants en vrac

Avantages de service
Takagi et al., The Plant Journal, 2013
● Localisation précise: mélange des volumes avec 30 + 30 à 200 + 200 personnes pour minimiser le bruit de fond; Prédiction de la région candidate non synonyme des mutatants.
● Analyse complète: Annotation de la fonction du gène candidate approfondie, y compris NR, Swissprot, Go, Kegg, COG, KOG, etc.
● Temps de redressement plus rapide: localisation rapide des gènes dans les 45 jours ouvrables.
● Expérience approfondie: BMK a contribué à des milliers de traits de localisation, couvrant diverses espèces comme les cultures, les produits aquatiques, les forêts, les fleurs, les fruits, etc.
Spécifications de service
Population:
Ségrégation de la descendance des parents avec des phénotypes opposés.
Par exemple F2 Progéniture, rétrocroisement (BC), ligne consanguine recombinante (RIL)
Mixage de piscine
Pour les traits qualitatifs: 30 à 50 individus (minimum 20) / vrac
Pour les tratitis quantitatifs: 5% des personnes supérieures à 10% avec l'un ou l'autre des phénotypes extrêmes dans toute la population (moins 30 + 30).
Profondeur de séquençage recommandée
Au moins 20x / parent et 1x / progéniture individuelle (par exemple pour le bassin de mixage de progéniture de 30 + 30 individus, la profondeur de séquençage sera de 30x par vrac)
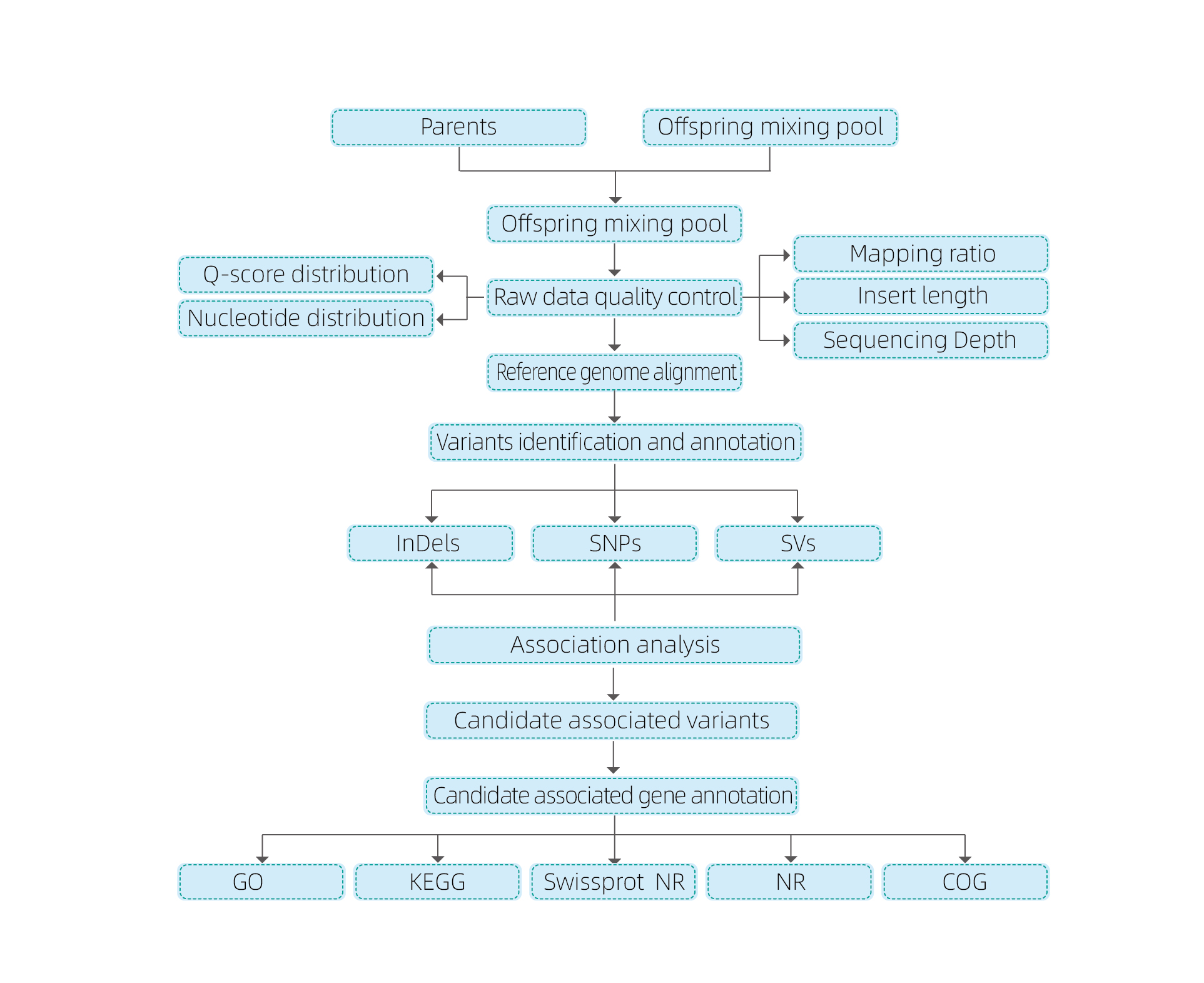
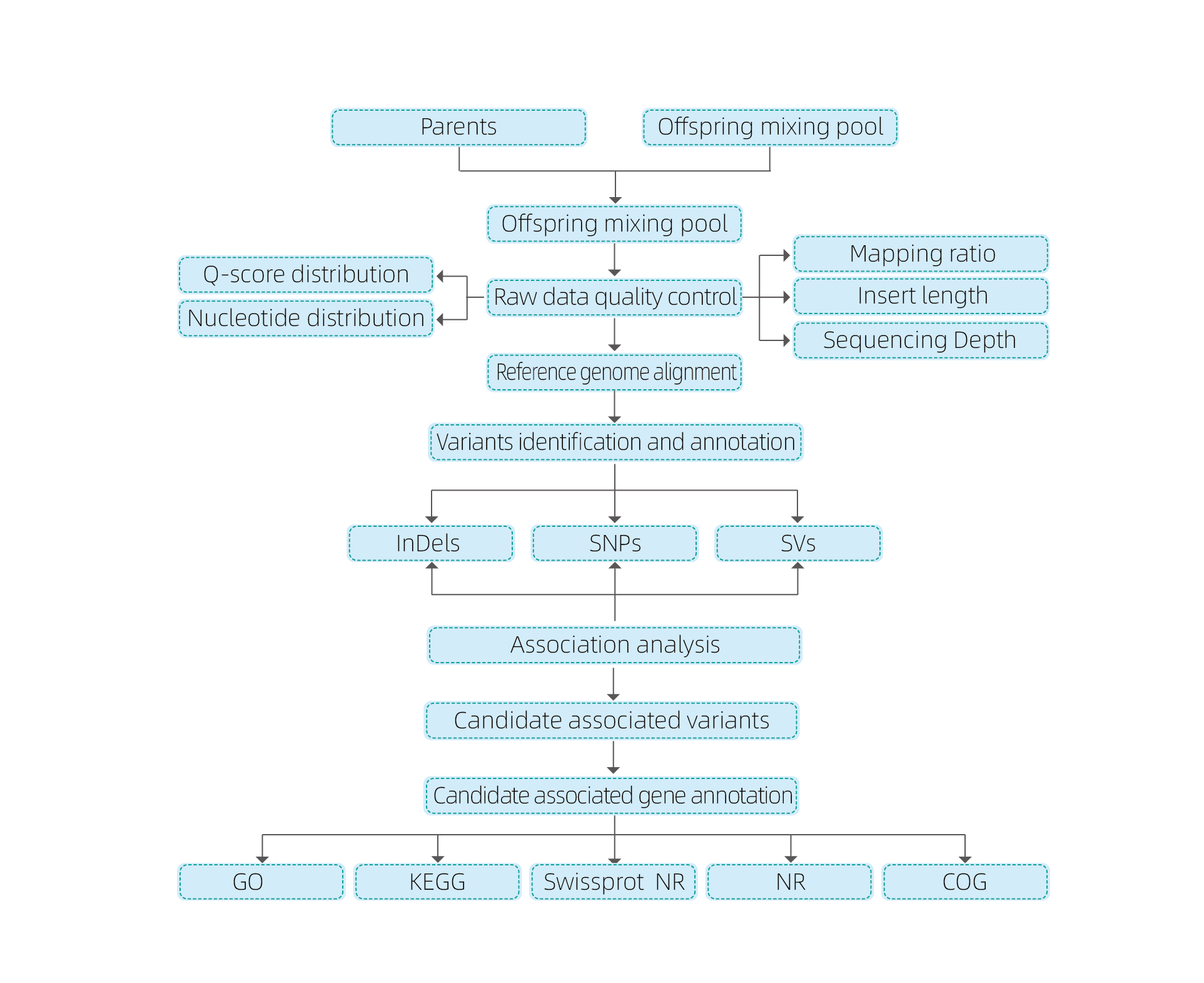
Analyses de bioinformatique
● Resqueur le génome entier
● Traitement des données
● appelle SNP / indel
● Dépistage de la région des candidats
● Annotation de la fonction du gène candidate
Exemples d'exigences et de livraison
Exemples d'exigences:
Nucléotides:
| échantillon de GDNA | Échantillon de tissu |
| Concentration: ≥30 ng / μl | Plantes: 1-2 g |
| Quantité: ≥ 2 μg (volume ≥15 μl) | Animaux: 0,5-1 g |
| Pureté: OD260 / 280 = 1,6-2.5 | Sang total: 1,5 ml |
Flux de travail de service

Conception d'expérience
Livraison d'échantillons
Extraction de l'ARN
Construction de la bibliothèque

Séquençage

Analyse des données
Services après-vente
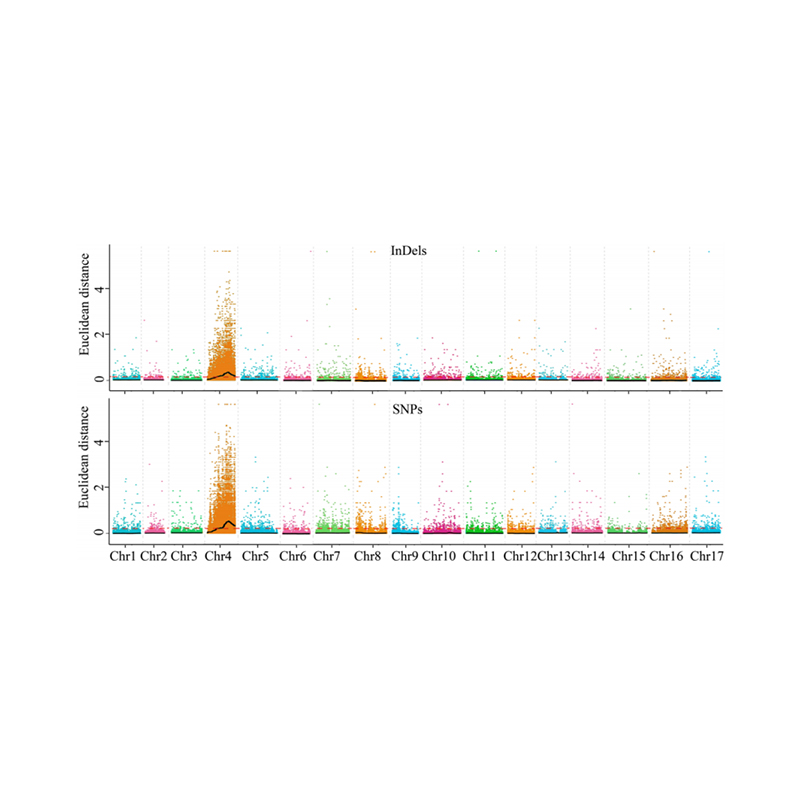
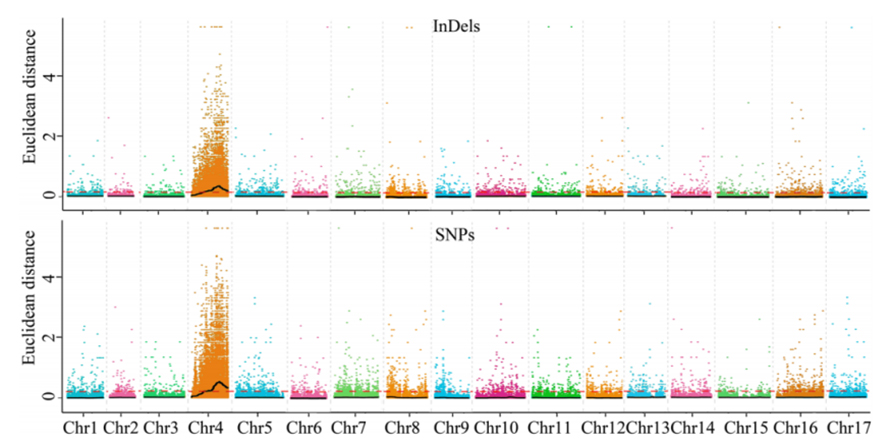
1. Base d'analyse d'association sur la distance euclidienne (ED) pour identifier la région candidate. Dans la figure suivante
Axe X: nombre de chromosomes; Chaque point représente une valeur ED d'un SNP. La ligne noire correspond à une valeur ED ajustée. Une valeur ED plus élevée indique une association plus significative entre le site et le phénotype. La ligne de tableau de bord rouge représente le seuil d'association significative.
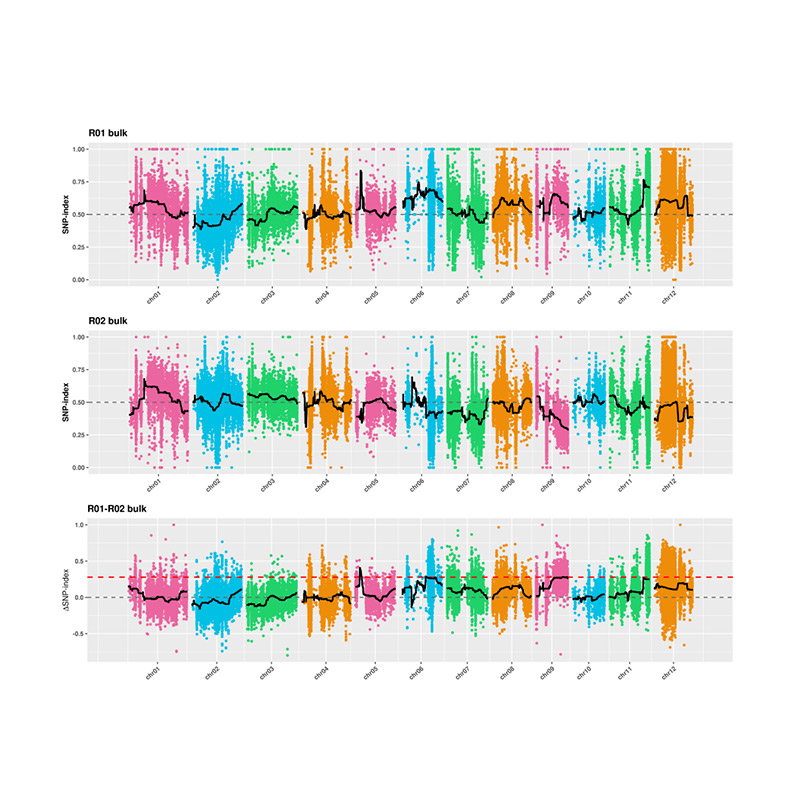
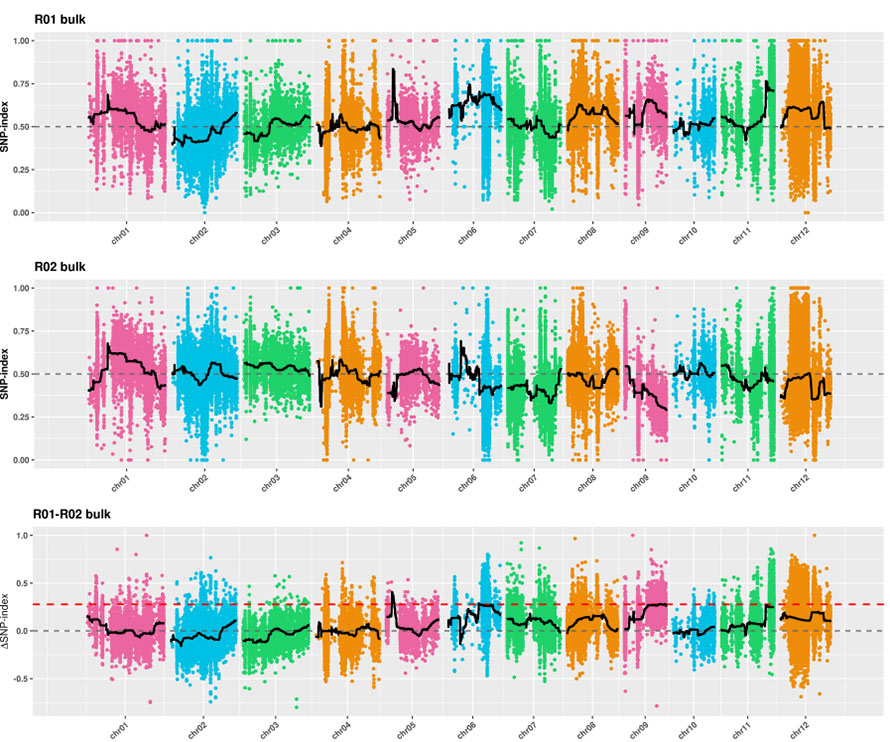
2. Analyse d'association basée sur l'indice SNP
Axe X: nombre de chromosomes; Chaque point représente la valeur SNP-index. La ligne noire représente la valeur SNP-index ajustée. Plus la valeur est grande, plus l'association est importante.
Cas de BMK
Le locus de traits quantitatifs à effet majeur FNL7.1 code pour une embryogenèse tardive protéine abondante associée à la longueur du cou de fruit dans le concombre
Publié: Journal de la biotechnologie végétale, 2020
Stratégie de séquençage:
Parents (JIN5-508, YN): Resqueur le génome entier pour 34 × et 20 ×.
Pools d'ADN (50 couches longs et 50 à col courte): Resqueur pour 61 × et 52 ×
Résultats clés
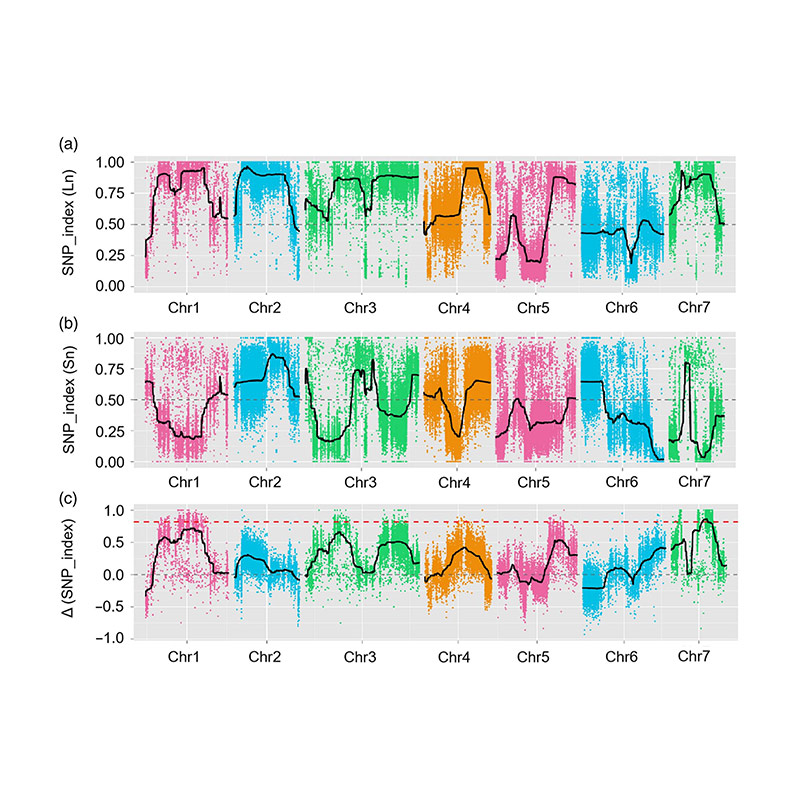
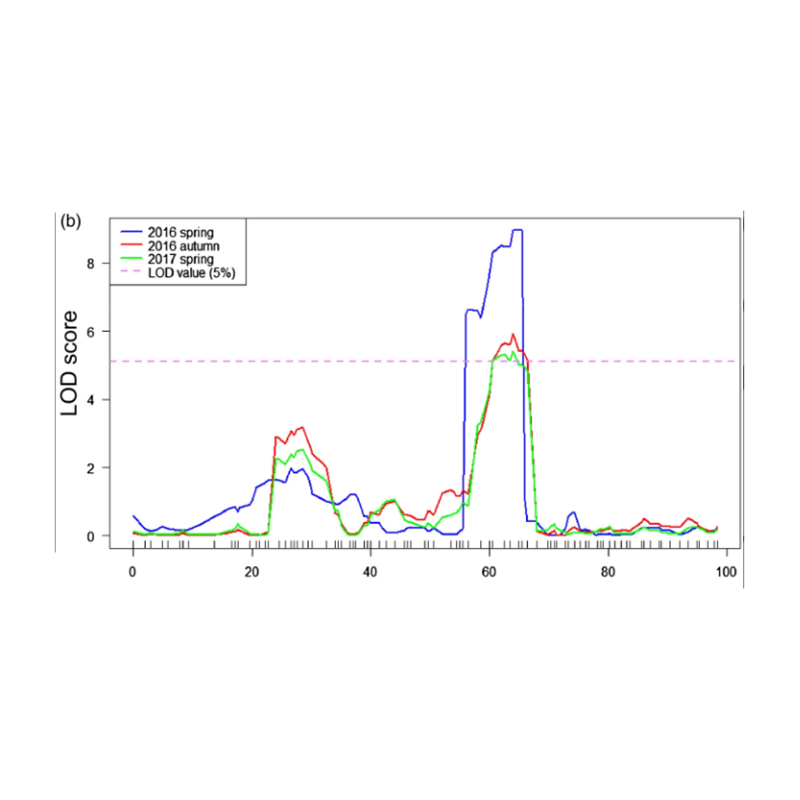
Dans cette étude, la population de ségrégation (F2 et F2: 3) a été générée en traversant la ligne de concombre à long cou JIN5-508 et le YN à col court. Deux piscines d'ADN ont été construites par 50 individus à long cou extrême et 50 individus à col courte extrême. Le QTL à effets majeurs a été identifié sur CHR07 par analyse BSA et cartographie traditionnelle QTL. La région candidate a été encore rétrécie par la cartographie fine, la quantification de l'expression des gènes et les expériences transgéniques, qui ont révélé un gène clé dans le contrôle de la longueur du cou, CSFNL7.1. De plus, le polymorphisme dans la région du promoteur CSFNL7.1 s'est avéré être associé à l'expression correspondante. Une analyse phylogénétique supplémentaire a suggéré que le locus FNL7.1 est très susceptible d'être originaire de l'Inde.
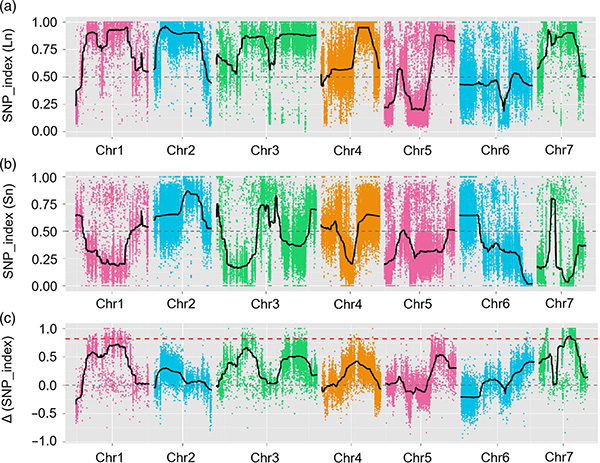 Mapping QTL dans l'analyse BSA pour identifier la région candidate associée à la longueur du cou du concombre | 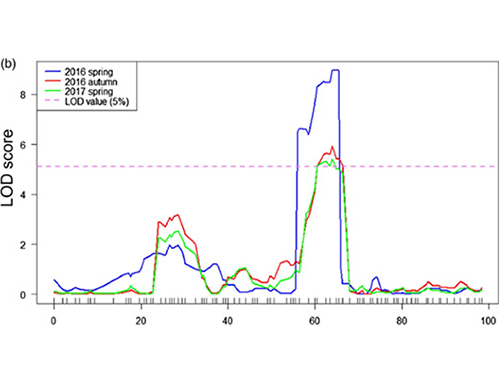 Profils LOD de la longueur de cou du concombre QTL identifié sur Chr07 |
Xu, X., et al. «Le locus de traits quantitatifs à effet majeur FNL7.1 code pour une embryogenèse tardive de protéine abondante associée à la longueur du cou de fruit dans le concombre.» Plant Biotechnology Journal 18.7 (2020).



